SPMIA
- 1 欢迎来到云的世界
- 2 使用Spring Boot构建微服务
- 3 使用Spring Cloud配置服务器
- 4 发现服务
- 5 构建客户端弹性模型——Netflix Hystrix
- 6 服务路由——Zuul
- 7 保护你的微服务(Securing)
- 8 事件驱动的架构——Spring Cloud Stream
- 9 分布式跟踪——Spring Cloud Sleuth & Zipkin
- 10 部署微服务
- NOTES:
英文版Spring Microservices in Action读书笔记。英文书的特点就是篇幅很长话很多,比较容易理解,适合初学者;但不好就是如果想要消化得好就读起来太慢
1 欢迎来到云的世界
什么是微服务
- 应用逻辑被拆分成很多组件,组件之间(功能/职责)界限分明,合作来完成一个项目
- 每个组件完成某一domain的小任务,可以独立部署。一个微服务应是可重用的。
- 组件之间基于一些原则进行通信——HTTP、JSON来进行数据交换
- 不关心用什么技术来实现(因为使用的是技术无关性的”协议“–JSON)
- 由于其小、独立、分布式的特点,这些微服务可以有很多个小团队实现
为什么可以用Spring来构建微服务
Spring是一个基于依赖注入的框架,不同于传统的Java应用中通过硬编码(类之间的相互调用)的方式将类进行链接(带来的坏处就是一旦编译完,类间的链接关系就不能改变了),Spring采用的是将类间的依赖/链接关系外部化(externalize),能够更好的管理依赖。
使用Spring Boot和Spring Cloud,我们可以更方便地开发分布式的微服务,并将它们部署到云上。
读这本书你可以学到
- 什么是微服务,如何设计构建一个微服务
- 什么时候不应该使用微服务
- 如何使用Spring Boot来构建微服务
- 构建微服务应用(基于云的)有哪些可行的pattern
- 怎样用Spring Cloud实现那些patterns
- 如何构建一个deployment pipeline,用于将服务部署到私有/公有云上
为什么要采用微服务架构
随着技术的发展,现代社会的方方面面都被互联网连接起来了。任何一款产品都可能面向全球的竞争者,开发者也遇到了更大的挑战:
- 复杂度上升——应用不再是单打独斗,往往需要和其他的应用进行交互。比如阿里的支付宝现在绝不仅仅只是一个手机支付的app,它甚至涵盖了出行的基本需要(需要用到钱的地方)
- 客户想要快速交付——用户没有耐心等待每一个新版本软件包的发行,他们希望每当更新了新的feature后可以很快地使用
- 性能和可扩展性——全球化(数量级)的应用使得很难预测应用的交易量能达到多少,应用必须有能快速在多台服务器之间进行扩展(scale up)、不需要时收缩(scale down)的能力
- 高可用性——用户希望应用是一直可用的,即不会崩溃或者出现什么bug
通过将服务改造成微服务架构,我们得到的应用将会是:小的、简单的、松耦合的,即可扩展的、适应性强的、灵活的。
什么是云
云计算的三种基本模型:
- Infrastructure as a Service(IaaS)
- Platform as a Service(PaaS)
- Software as a Service(SaaS)
除此之外,还有一些新兴的云平台类型,如:
- Function as a Service(FaaS)
- Container as a Service(CaaS)
FaaS使用到的技术如Amazon的Lambda技术以及Google Cloud Functions,构建出“Serverless”的应用可以完全运行在云服务提供商的计算平台。
CaaS指的就是将微服务作为便携的(portable)虚拟容器(如Docker)部署到云上。不像IaaS(你需要管理你的虚拟机器),你可以直接使用云服务提供商提供的工具来构建、发布、监测、扩展等等。Amazon的ECS(弹性容器服务)就是一例。
云和微服务
写好了微服务,一般来说有三种方式部署
- 物理服务器——不易扩展
- 虚拟机器镜像——易扩展
- 虚拟容器——易扩展,且较轻量级
基于云的微服务最大的好处就是可伸缩性,即增强了它的横向扩展能力。
本书中使用Docker将微服务部署到基于IaaS的云上。
- 简化基础设施管理——通过简单的API调用,即可实现对基础设施的管理
- 强大的横向扩展能力——可以很快地开启多个实例
- 多地配置带来的高冗余性——通常云提供商会在多个地理位置拥有数据中心
为什么不使用PaaS?
在这么多云服务模型中,IaaS是提供的服务最少的,只有Infrastructure,同时也是最灵活的,因为其它的部分你可以自己选择。之所以选择IaaS是因为当我们的微服务变得越来越多时,需要更大的灵活性。
使用PaaS你可以将应用作为JAR包或者WAR包部署上去。你不需要设置/修改应用服务器和相关的Java容器,这一点比较方便。
另外,基于FaaS的平台将会使你更加受限制。因为你虽然可以用自己熟悉的语言来写自己的服务,但是你需要严重依赖vendor提供的API和运行时引擎(runtime engine)(只有在那个引擎上你的应用才能正确function)。
1.9 微服务不只是写代码
构建一个robust的微服务不只是写写代码。有几件事需要考虑:
- 大小适中——确保每一个微服务的职责边界大小合适,只有这样才能方便对应用做出修改并在特殊情况下降低风险
- 定位透明(?)——怎样管理服务调用时的物理细节,多个实例可以快速启动/关闭
- 灵活性——当服务fail时怎么通过路由(routing)保证应用的完整性,保护用户【就是错误处理吧】
- 可复现——怎样确保服务中的每一个新的实例都有和生产环境中的实例相同的配置和code base(代码库)
- 可扩展——怎么使用异步处理和事件来减少服务之间的直接依赖,并保证可扩展性
接下来,介绍六个微服务模式:
- Core Development Pattern
- 路由模式
- 客户端灵活性(resiliency)模式
- 安全模式
- 日志和轨迹(trace)模式
- 构建和开发模式
1.9.1 核心开发模式
- 服务粒度——怎样将业务(business domain)拆分成适当的微服务?若分的太粗略则职责会overlap;若分得太细则增加了应用的复杂度
- 通信协议——JSON?XML?
- 接口设计——怎样设计接口以供开发者调用?好的接口设计是intuitive,即让人看到你的接口就知道它是做什么的
- 配置管理——怎样管理配置才能做到在不同云环境无需改动核心应用代码和配置
- 事件处理——怎样通过事件处理将硬编码部分减到最少,增加应用的灵活性(resiliency)
1.9.2 路由模式
routing pattern要解决的是要使用微服务的客户端如何发现服务的location并被路由过去。
在基于云的应用中,你可能有很多微服务实例同时在运行。你应该将这些服务的物理地址抽象出来,为服务调用提供一个统一的入口,以便一直保持应用的安全性。
- Service discovery——怎样设计(不通过硬编码service的location)使得你的服务容易被发现?怎样保证不能正确执行的微服务实例能够从可运行的服务实例中抽出?
- Service routing——怎样为不同服务设计统一入口?
1.9.3 客户端灵活性
微服务架构是高度分布式的,所以要特别注意某一服务中的问题会级联(影响)到其他的用户。为此,我们有以下四种模型:
- 客户端负载均衡——怎样在客户端缓存服务实例的地址(location)以便对某个包含多个实例的微服务的调用(请求)能被均衡的分发到所有正常运行的微服务实例中?
- 电路断路器模式——怎样让一个客户端在请求失败或者遭遇性能问题时停止请求?当某个服务遭遇性能瓶颈,它会消耗调用它的客户端的资源。应该做到让微服务调用fail fast(死得快)来提醒客户端快速做出反应
- 撤退模式(Fallback)——当一个微服务fail时,怎样提供一个插件机制使客户端能够通过别的方式而不是调用这个坏掉的服务的方式完成工作
- 隔板模式(Bulkhead)——微服务使用分布式的资源来完成工作。怎样划分这些调用请求以防止某个服务失效影响到其他服务?
1.9.4 安全模式(Security)
- Authentication(验证)——验证客户端的身份
- Authorization(授权)——确定客户端有权限使用服务(确定了client的身份后)
- Credential management and propagation(证书管理和传播)——怎样使客户端不需要么次调用服务时都需要出示证书?可以使用基于token的安全标准,如OAuth2和JavaScript Web Tokens(JWT),获得的token用来在服务与服务之间验证并为用户授权。
1.9.5 日志和追踪(tracing)模式
- 日志关系(correlation)——怎样将同一个用户交易(transaction)下的不同微服务的所有日志绑定在一起?可以实现一个关系ID(correlation ID),作为一个单独的标识符,在一次事务的不同服务之间作为标识。
- 日志聚合(aggregation)——如何将微服务产生的所有日志放到一起组成一个可查询的数据库?可以借助correlation ID。
- 微服务轨迹(tracing)——怎么将一个客户端交易事务所涉及的所有微服务的流程可视化,并分析其中的性能
1.9.6 构建/发布模式
为了构建immutable infrastructure,我们需要确保一个服务的任何实例都与其他实例是不同的,并且一旦一个服务部署上去,它所在的infrastructure再也不会改变了。
构建/发布pipeline——怎样创造一个可重复的构建/发布过程,可以一键构建/部署到任何环境?
Infrastructure as code——怎样做到“服务即代码”,即可以被执行,源代码被管理
不变的服务器——一旦一个微服务的镜像被创建了,怎样保证在发布之后不被改变?
Phoenix servers——服务器运行时间越长,越容易发生configuration drift(配置漂移)(配置发生变化)。怎样保证日常崩溃的服务器能由一个不变的镜像恢复重建?
1.10 使用Spring Cloud构建微服务
使用Spring Cloud构建微服务的好处就是它集成了很多开发需要用到的patterns。
1.10.1 Spring Boot
Spring Boot极大简化了基于REST的微服务构建过程;简化了HTTP动词和URL的映射;简化了JSON协议和Java对象的序列化;简化了Java异常和HTTP异常代码的映射。
1.10.2 Spring Cloud Config
Spring Cloud Config通过中心化的服务来处理管理应用的配置数据,使得应用的配置数据与服务分开。好处是无论新增了多少微服务实例,都可以拥有相同的配置。除了自己的property管理仓库,还集成了许多开源项目,如:
- Git:版本控制系统
- Consul:开源的、服务发现工具。你可以用来注册自己的服务,客户端可以询问Consul服务的位置。Consul也包括一个key-value数据库,可以存储应用配置数据
- Eureka:开源的Netflix项目,与Consul类似
1.10.3 Spring Cloud Service Discovery
通过Spring Cloud,你可以把你服务器的物理地址抽象化,服务使用者(客户端)可以通过一个逻辑名而不是物理location来访问。Spring Cloud同样处理服务实例的注册与注销。可以使用Consul作为服务发现引擎。
1.10.4 Spring Cloud/Netflix Hystrix and Ribbon
Spring Cloud集成了很多Netflix的开源项目。对于客户端灵活性模式,Spring Cloud使用Netflix Hystrix库和Ribbon项目来完成。
使用Hystrix库,你可以很快实现客户端弹性模式,如断路器模式和舱壁模式
1.10.5 Spring Cloud/Netflix Zuul
Netflix Zuul为微服务应用提供服务路由功能。Zuul是代理服务请求的服务网关,通过集中的服务调用,开发人员可以强制执行服务策略,如安全验证、内容过滤和路由规则。
1.10.6 Spring Cloud Stream
可以通过Stream将轻量级消息处理集成到微服务中。借助它,开发人员能够构建智能的微服务,它可以使用在应用程序中出现的异步事件。此外,Stream可以将微服务与消息代理整合,如RabbitMQ和Kafka。
1.10.7 Spring Cloud Sleuth
Sleuth让你可以将唯一的tracking identifiers(跟踪标识符)集成到HTTP调用和消息通道中(RabbitMQ、Kafka)。这些tracking number(跟踪号码),也叫correlation/trace Id(关联Id)可以在应用程序的不同的服务中跟踪一个事务/交易。使用Sleuth,这些trace ID会自动添加到日志中。
Sleuth真正大放异彩是和日志聚合工具如Papertrail和跟踪工具如Zipkin等结合的时候。Papertrail是一个基于云的日志平台,可以实时将不同微服务产生的日志聚合成一个可查询的数据库。Zipkin可以将Sleuth产生的数据通过可视化的方式来展示某次事务/交易中涉及的服务调用(service call)工作流(flow)。
1.10.7 Spring Cloud Security
这是一个用于验证(authentication)和授权(authorization)的框架,可以控制访问本服务的人员和他们的权限。Spring Cloud Security是基于token的,允许服务之间通过认证服务器(authentication server)授予的token来通信。每当服务接收到调用请求,会检查HTTP请求附带的token,验证其身份和访问权限。
此外,Security支持JWT。JWT框架可以标准化一个OAuth2token的创建格式,并为创建令牌进行数字签名提供了标准。
1.10.8 代码供应(provisioning)
提到代码供应,我们需要额外的技术栈。Spring框架是一个面向应用开发的框架,并不包括构建/部署的工具。要实现一个build and development pipeline,你需要使用Travis CI作为构建工具,用Docker来构建包含微服务的服务器镜像。
1.11 Spring Cloud完整的小例子
1.12 本书要完成的项目
1.13 总结
- 微服务是很小的一个功能模块,负责特定的领域
- 没有行业标准,不像其他网络服务协议,微服务采用基于原则的方法,与REST和JSON相似
- 写微服务很容易,当将其完全用于生产(production)需要多加考虑。包含要实现的几种模式(上文讲到的)
- 虽然微服务与语言无关,但本书引入两个框架:Spring Boot和Spring Cloud
- Spring Boot是为了简化基于REST/JSON的微服务的开发的
- Spring Cloud是一系列开源技术的集合(包括Netflix下的项目)
2 使用Spring Boot构建微服务
2.1 架构师的故事——设计微服务架构
三个关键任务:
- 分解业务问题
- 建立服务粒度
- 定义服务接口
2.1.1 分解业务问题
- 描述业务,注意名词:contracts(合同)、licenses(许可证)、assets(资产)。
- 注意动词:查找、更新。
- 寻找数据内聚(cohesion):寻找数据之间的关系。每个微服务应该只包含自己的数据。
EagleEye的数据模型可以简化为四个部分:Organization、License、Contract、Assets。
2.1.2 建立服务粒度(granularity)
基于数据模型,我们将在以下四个元素上建立微服务:
- Assets
- License
- Contract
- Organization
如何建立合适的粒度?
- 由大到小——开始的时候先比较粗略地划分一下,之后将问题域逐渐细分,直到找到一个比较好的大小。否则,开始就划分太细会导致应用复杂度过大。
- 注意交互——有助于建立服务的粗粒度接口,由粗到细是比较容易的
- 服务职责会改变——当需要新的应用功能时,服务就会有新的职责。最初的微服务可能会拆分成多个微服务,原始的微服务作为这些新服务的编排层(orchestration/arrangement),负责将应用其他部分的功能封装起来。
“糟糕”的微服务
- 服务承担过多的职责——某个服务的业务逻辑很复杂
- 服务管理了太多的数据表——服务需要使用很多表来管理数据,每个服务应该只管理自己的数据,其他的通过交互/通信实现,一个服务最好包含3-5张表
- 太多的测试用例——每个微服务可能随着时间增长。开始就有很多测试用例,增长空间会变得很小
- 粒度太细的微服务:
- Everything都是一个微服务,每个服务只和一个数据库表打交道
- 服务之间互相依赖严重——为了完成一个用户请求,一个服务需要来来回回调用其他的服务
- 微服务成为简单CRUD的集合——微服务是业务逻辑的表达,而不只是数据源的抽象层
2.1.3 交互:定义服务接口
- 拥抱REST理念
- 使用URI来传递意图(intent)——作为服务端点的URI描述问题域中的不同资源,并能表示出资源之间的关系
- 请求和响应使用JSON——轻量级的数据序列化协议
- 使用HTTP状态码表示结果——用HTTP状态码表示服务的成功/失败
2.2 什么时候不使用微服务
- 构建分布式系统的复杂性
- 虚拟服务器/容器散乱
- 应用类型
- 数据事务和一致性
2.2.1 构建分布式系统的复杂性
由于微服务是分布式的且细粒度的,构建起来往往比构建单体应用程序更复杂。微服务架构需要一个很高的运维成熟度(operational maturity)。除非部门愿意投入高分布式应用程序所需要的自动化以及运维工作(监控,scale up/down),否则不要考虑使用微服务。
2.2.2 服务器散乱
微服务最常用的部署方式就是一个服务器上部署一个微服务实例。在一个基于微服务的大型应用中,最终可能需要建设和维护50~100台服务器。即使在云上运行这些服务成本比较低,管理和监控这些机器的复杂度也是巨大的。
注意
必须对微服务的灵活性和运行多台机器的成本(复杂性)进行权衡。
2.2.3 应用程序的类型
微服务的一个特点是提高可重用性,对构建需要高度弹性(resilient)和可伸缩性(scalable)的大型应用非常有用。这也是很多基于云的公司采用微服务架构的原因。如果构建一个小型的、部门级的应用或者只有很小的用户群
,构建分布式的模型(如微服务)将会成本太高,不值得。
2.2.4 数据事务和一致性
当你观察微服务时,你需要注意的是服务的数据使用模式和消费者如何使用它们。微服务包装并抽象出少量的表,作为执行“操作型”任务的机制,如针对存储的创建、增加和简单查询。
如果应用程序需要对多个数据源做一些复杂的数据聚合或者转换,微服务的分布式特点将会使这个过程变得很困难。你的微服务将会承担太多的职责,也很容易受性能问题的影响。
记住,在微服务间执行事务没有统一标准。如果需要事务处理,那就得自己构建这个逻辑。从第七章可以看到,微服务间可以通过消息进行通信,消息传递在更新过程中就带来了延迟。你的应用需要处理最终的一致性(数据的更新可能不会立即出现)。
2.3 开发者故事:使用Spring Boot和Java构建一个微服务
在本部分,我们将实现构建EagleEye应用的许可证(licensing)微服务。接下来几节将要:
- 搭建微服务框架,构建应用程序的Maven脚本
- 实现一个Spring的启动类,用于启动装载微服务的容器并启动所有类的初始化工作
- 实现一个Spring Boot控制器类(controller)来映射服务请求的端点
在本例中,实现了简单的get、put、post、delete方法,与HTTP动作对应。但是,目前只是简单实现了get,可以通过url中的变量来改变get到的结果。
** @RestController与*@Controller*的不同点:**
@RestController实现了REST风格的controller,返回JSON类型的数据,并且不需要增加*@ResponseBody*的注解;
@Controller只是返回一个普通的Response对象(当然要加上*@ResponseBody*注解),并且可以返回正确的jsp、html页面,由配置好的视图解析器(InternalResourceViewResolver)完成。
** @RequestMapping的level**
可以用来修饰类,也可以用来修饰方法。
Endpoint命名很重要!
Endpoint的名字就是每一个微服务的URL路径。命名时注意三点:
- 使用清晰的命名方式——尽量使命名一致且易读,能够一眼就看出来代表的什么资源
- 建立资源之间的关系——资源之间通常存在层级关系,如
spring-boot/docs/hello-world.html。因此一个孩子不能单独地存在于父节点之外。若你的URL太长了(嵌套太多层),可能你的微服务需要重写(服务范围太大了)。 - 在URL中标识版本号——URL代表了服务提供者和消费者之间的一种契约关系。最好将一个版本号放在所有端点前面。如
v1/organizations/e254f8c
2.4 开发者故事:构建运行时的严谨性
从开发者的角度,要遵循四个原则:
- 每个微服务应该自包含、可独立部署,并且在一个软件构件(artifact)中包含多个服务的实例(instances of service)
- 每个微服务应是可配置的。当服务启动时,它应该自动读取需要的配置数据(从central location或是从环境变量中),无需人工干预。
- 每个微服务实例应该对客户端是透明的。客户端不知道服务的确切位置(物理地址),客户端永远和代理(agent)打交道。
- 每个微服务可以报告它的health情况。这是云架构的关键部分。一旦某个实例无法正常运行,客户端需要被路由到正常的服务实例。
从运维(DevOps)的角度,这四条原则可以映射到以下的运维生命周期:
- 服务装配——怎样打包部署微服务来保证其可重复性与一致性,使得相同的服务代码和运行时环境以相同方式部署
- 服务引导/启动(bootstraping)——怎样将应用代码和与特定环境相关的配置代码分离,使得每次部署到新环境能够快速启动/发布,无需人工干预配置
- 服务注册/发现——当一个微服务实例被发布,怎样使其更容易被其他应用发现(discoverable)?
- 服务监控——微服务开发中,为了保证高可用性,通常一个服务有多个实例在运行。运维需要负责任何运行故障的监控与处理,并且将失效的服务拆卸掉。
构建12-factor微服务应用程序
一个成功的微服务架构需要很多的开发与运维实践经验。有一个12因素应用宣言,所谓最佳实践(Best Practices),原文可以在https://12factor.net找到,总结如下:
代码库——所有应用代码和服务器供应信息都应处于版本控制中。每个微服务在版本控制系统中应该有独立的代码仓库。
依赖——通过构建工具(如Maven)显式地(explicitly)声明依赖。第三发jar依赖应该明确其版本号。这样能够保证微服务始终用同样的版本库来构。
配置——将配置代码和应用程序源代码分开。
后端服务——微服务通过网络与数据库或消息系统进行通信。应该保证,任何时候都可以将本地管理的服务换成第三方服务。第10章,我们将从本地的Postgres数据库迁移到Amazon管理的数据库。
构建、发布和运行——保持应用程序的构建、发布和运行过程分离。一旦代码构建完成,在运行时就不要再改动代码。一旦改动,就要重新构建发布。一个已构建服务是不可变的(immutable)。
进程——微服务始终是无状态的。它们可以在任何时候被撤销和替换,不用担心服务实例的丢失会导致数据丢失。
端口绑定——一个微服务在打包时是完全独立的,其中包含了运行时引擎。因此,运行微服务不需要额外的web或应用服务器,服务可以在命令行自启动,通过暴露的HTTP端口访问。
并发——当你需要扩展(scale),不要依赖于单一服务的线程模型,而是创建更多服务实例来横向扩展。相对来说,单一服务的线程模型(scale up)量级不够大,多服务实例(scale out)更加易扩展。
可处理性(disposability)——微服务是可以任意处置的,可以随时被启动和停止。应最小化启动时间,当被kill时应能够正常退出。
开发/生产环境同等对待——减小服务在不同环境中运行的差异。开发者在本地开发时的基础设施(infrastructure)应与服务发布后运行时的相同 。这也意味着服务能够快速部署,代码被提交后,应该被测试,然后尽快从测试环境一直promote到生产环境。
日志——日志是一个事件流。当日志被写出时,应该可以流式传输到Splunk或Fluentd这样的工具,通过校对整理将它们写到中央位置。微服务不需要关心这种情况发生的机制,开发者可以通过STDOUT查看日志。
管理进程——开发人员经常需要对所写的服务进行管理工作(数据迁移、转换等)。应当用脚本来完成这些工作。脚本应该是可重复的,并且在每个运行的环境中是不可变的(不需要针对每个环境进行修改)。
2.4.1 服务装配——打包部署你的微服务
通常,基于Java的微服务框架都包含一个运行时引擎,如Spring Boot。可以从命令行运行,如:
1 | mvn clean package && java -jar target/licensing-service-0.0.1-SNAPSHOT.jar |
传统的J2EE开发中。应用是被部署到一个应用服务器上的。这样的应用只包含应用实体,需要被系统管理员团队根据不同的部署运行环境管理不同的配置。
这种做法——将应用服务器的配置和应用程序分离,在部署过程中引入了更多故障点(failure points),因为很多组织的应用服务器的配置不受源控制(source control),而是通过用户界面(UI)和本地管理脚本组合的方式来控制。这很容易在服务环境中发生configuration drift,并突然导致服务中断(outage)。
将运行时引擎嵌入应用的做法减少了配置漂移的可能性(因为统一位于源代码控制),这样也允许开发团队更好地思考他们的app是如何构建/部署的。
2.4.2 服务引导:配置管理
当应用程序启动时,需要先从配置文件或者数据存储仓库(如数据库)读取配置数据,微服务也不例外。但是,对于成百上千的微服务实例,每当配置数据更新了后重新部署微服务似乎不太可行。
把配置数据存储在服务外部通常是个解决方法,但是基于云的微服务还需要考虑以下几点:
- 配置数据数据结构要简单,经常读取不常写入。最好不要用关系型数据库,因为关系型数据库的数据类型很复杂,大材小用。
- 数据定期访问,但是很少更改,因此读数据要做到低延迟。
- 数据仓库应是高可用的,且靠近(地理上)需要读数据的服务。配置数据仓库不能完全关闭,否则会导致单点故障。
2.4.3 服务注册与发现:客户端如何与微服务通信
从微服务consumer的角度来看,一个微服务应当是地理位置透明的(不关心地理位置)。在基于云的环境中,服务器是短暂的(不固定的),不同于传统的位于企业数据中心的服务器。服务可以很快地启动/停止,被分配新的IP。
由于微服务的“短暂性”特征,它因此获得了高度的可扩展性、可用性以及灵活性。同时带来了一个问题——手工管理大量的短暂服务很容易造成运行中断(还话费大量人力)。
一个微服务,一个成熟的微服务(没错,**你已经是个成熟的微服务了**),应该会自己找到第三方代理并把自己注册上,这个过程也叫服务发现(service discovery)。
所谓的把自己注册到服务发现的代理,是指将两个东西告诉服务发现代理:
- 物理IP地址,或者服务实例的域名地址(domain address)
- 应用可以用来查看服务的逻辑名
某些服务发现代理还需要一个URL(注册代理的那个服务的),以便于代理进行健康检查(检查服务实例的运行情况)。然后,服务客户端就可以通过代理来查看服务的位置。
2.4.4 报告微服务的健康状况
服务发现代理的任务不仅是像一个交通警察一样将客户端带到相应服务的位置,还要持续监视每一个微服务实例的运行情况,以确保客户端不会将请求发送到一个无效的服务实例上。
微服务开始运行后,服务发现代理会持续地监视并向健康检查接口(health check interface)发送ping报文,以确保服务可用。
通过构建一个一致的接口,可以使用基于云的监视工具来检测问题并反馈(如检测到异常后关闭服务等等)。
如果使用REST风格构建微服务,通常暴露一个HTTP端点,返回一个JSON类型的payload和HTTP状态码。如果没有使用类似Spring Boot的框架,则需要开发者自己手动实现端点;但是有了Spring Boot提供的开箱即用(out-of-the-box)的Spring Actuator组件,可以快速实现健康检查的接口。
在pom.xml中添加了依赖后,在地址栏输入http://localhost:8080/health可以看到返回的健康数据。
2.5 以上帝视角看问题
- 架构师——专注于业务问题的轮廓,分析出备选的微服务。记住,要从粗到细,一开始就把服务划分的过细不是个好习惯。
- 软件工程师——尽管(每个)微服务很小,这并不意味着将良好的设计原则抛之脑后。服务中的每一层都有明确的职责。避免在代码中构建框架,尝试使每个微服务完全独立。不成熟的框架设计只会带来生命周期的后期巨大的维护代价。
- 运维工程师——服务的存在需要介质,要尽早的建立服务的生命周期。运维不止要关注如何自动化构建和发布过程,更要关注如何监视服务的运行状况以及服务出现问题时怎么办。
3 使用Spring Cloud配置服务器
开发人员需要注意的一点是,尽量把应用代码和配置信息分离开,即在应用程序中应不包含关于配置的任何信息。这样的一个好处是,由于应用代码部分没有关于配置的硬编码信息,每当配置发生了改变,不需要重新编译/部署。同时带来了一个问题,配置部分要作为一个单独的artifact进行管理和发布。
许多开发者会将配置信息放到低层级的属性(配置)文件(如YAML、JSON或XML)中。它放在服务器上,包含数据库或者中间件的连接信息,以及关于此应用的一些元数据(metadata)用来引导应用程序的行为。此种方式比较简单,大多数开发者也都是这么做的——将配置文件放到源代码控制,作为应用的一部分部署。
上述方法对于一些应用可行,但是对于基于云的应用(通常包含许多微服务,每个微服务还有很多实例,就不太行了。
对于配置管理,基于云的微服务开发强调:
应用程序配置和被部署的代码完全分开
构建好服务器、应用以及一个永远不会改变的镜像
在服务启动时注入应用的配置信息,通过读取环境变量或者中心仓库的方式。
3.1 配置管理(复杂性)
每当运维工程师需要手动配置或者改变服务时,都可能引起configuration drift、宕机或者延迟等问题,因此配置管理非常重要。配置管理的四个原则:
- 分离——服务的物理部署应与配置信息分离开。应用程序配置不应该与服务实例一同部署。配置信息应当在服务启动时作为环境变量传递给服务或者从中央仓库读取。
- 抽象——将访问配置数据的功能抽象到一个服务接口中。应用程序使用基于REST的JSON服务来检索配置数据,而不是直接访问服务存储仓库(即通过文件或者使用JDBC从数据库读取数据)。
- 中心化——基于云的应用程序可能有很多个服务,尽量减少保存配置信息的存储库。
- 稳定——由于配置信息和实际代码完全隔离,要保证其高可用性和冗余性
由于将配置信息置于实际代码之外,它将作为一个外部依赖,需要进行单独管理并进行版本控制。
On accidental complexity
3.1.1 配置管理架构
配置管理过程中,发生了以下重要的活动:
- 当一个微服务实例启动时,它将会调用一个服务endpoint来读取它所在特定的环境的配置信息。服务启动后,用于配置管理的连接信息(连接credentials(证书/凭据)、服务端点等)将会传递进来。
- 实际的配置存在于一个配置库(repository)中。可以使用不同的实现来保存配置数据。配置库的实现选择包括源代码控制下的文件、关系型数据库或是键值数据库。
- 应用程序的配置管理与应用程序的部署方式无关。配置管理的更改通常由构建/部署管道(build and deployment pipeline)来处理,配置的改变会被标记上版本信息并部署到不同环境中。
- 当配置管理发生了改变,使用这个配置信息的服务必须被通知(notify)并刷新应用程序数据的副本。
3.1.2 实现方式
对比了一下常用的开源项目,最终选定Spring Cloud configuration server
3.2 构建Spring Cloud配置服务器
本章我们要新建一个单独的目录——confsvr。在此目录下,需要新建一个pom.xml并把启动Spring Cloud配置服务器要用到的jar包添加上。
从pom.xml中可以发现描述Spring Boot的版本和Spring Cloud的版本并不相同。前者使用的是如1.4.4这样的版本号;后者使用的是一个叫release train的东西,版本号以伦敦地铁站名命名,如Angel,Brixton和Camden(很奇葩是不是?一个版本号都要搞这么多幺蛾子)。
3.2.1 创建Spring Cloud Config启动类
启动类中,多了一个*@EnableConfigServer*的注解,表明这是一个Spring Cloud Config的服务。
3.2.2 通过文件系统使用配置服务器
在application.yml文件中,可以通过文件系统或者基于云的Git提供商(如BitBucket或者GitHub)配置服务器。通过文件系统(本机)配置文件如下:
1 | server: |
8888指定了配置服务器运行的端口号;native说明了使用文件系统存储配置信息;searchLocations制定配置文件位置(使用相对路径)。
通过向配置服务器发送get请求:http://localhost:8888/licensingservice/default,可以看到以JSON格式返回的位于licensingservice.yml中的配置信息。将URL最后的endpoint换成dev,则会得到dev和default两个配置。这是因为Spring Cloud实现了一个层级的读取配置的机制。它首先寻找default,然后若找到更高层级的,则会覆盖default中已有的,即如果在default和dev中同时设置了某个属性值,则使用dev中的;否则,使用default中的。
3.3 将Spring Cloud Config集成到Spring Cloud客户端
上节只是将读取了硬编码的licensing service的配置,本节将通过与数据库交互来读取配置数据。
3.3.1 建立依赖
依次添加spring-boot-starter-data-jpa、postgresql、spring-cloud-config-client依赖包,引入Spring Data Java持久层API、Postgres JDBC驱动。最后一个依赖包含了和Spring Cloud配置服务器交互用到的所有的类。
3.3.2 配置许可证服务使用Spring Cloud Config
添加完依赖,我们需要将写好的服务(licensing service)也做相关配置,以告诉我们的服务到哪去找配置(连接配置服务器)。对于Spring Cloud Config,配置信息可以放在以下两个文件中:bootstrap.yml和application.yml。(两个配置文件都在src/main/resources目录下)
bootstrap.yml会读取应用的属性,且优先级最高。一般来说,其中包含了应用的名字、应用的profile(使用哪个配置profile)以及连接到配置服务器的URI。其它想设置的配置信息可以放在服务的外面——application.yml(而不是在配置服务器上)。通常,放在application.yml中的配置信息是你认为当配置服务器不可用时也能执行的。
bootstrap.yml内容如下:
1 | spring: |
其中,spring.application.name是应用的名字,并且必须与Spring Cloud配置服务器下的目录对应。如:若有一个服务licensingservice,则在配置服务器的src/main/resources/config下要有一个licensingservice的目录与之对应。
spring.profiles.active指出Spring Boot要使用哪个profile来运行。每一个profile对应一份不同的配置。
spring.cloud.config.uri指出服务应当从哪个endpoint寻找(连接)Spring Cloud配置服务器。默认使用端口8888。
3.3.3 使用数据源
本项目使用的是Spring Data JPA(一个封装了JPA规范的框架),可以通过约定好的方法命名规则写dao接口,就可以在不写接口实现的情况下,还实现对数据库的访问。提供了出CRUD之外的功能,如分页、排序、复杂查询等。项目中LicenseRepository的实现如下:
1 |
|
基本的命名规则形如 findByXXId 。通常,可以继承JpaRepository或CrudRepository。其中,JpaRepository继承自PagingAndSortingRepository,后者又继承自CrudRepository。顾名思义,Crud提供了CRUD的相关方法;PagingAndSorting提供了分页排序的方法;Jpa实现了一组Jpa规范的方法。
@Repository注解表示这个接口作为一个repository,可以自动产生一个动态代理。
3.3.4 使用@Value读取属性
配置类ServiceConfig类中,有一个*@Value*标记,它会自动把关于数据库的配置数据注入到数据库连接对象中。
1 |
|
通过@Value注解,Spring会自动从Spring Cloud配置服务器寻找example.property属性,并把其值注入到ServiceConfig类中。
3.3.5 通过Git使用Spring Cloud配置服务器
使用Git来管理配置属性(property)的好处就是,你的所有配置属性的管理也在源控制(source control)下。每当你重新构建/部署应用时,配置也可以同步构建/部署。
要将Git作为我们的配置服务器的配置信息的存放地点,需要更改application.yml文件。
1 | server: |
如果用文件系统作为配置服务器,则server下为native,此处为git。searchPaths指明了配置文件所在的路径。
3.3.6 刷新配置属性(property)
当配置改变时,如何使应用使用最新的配置?
可以在应用的启动类前加上*@RefreshSCope**注解,它会重新加载你自己写的(额外的)属性配置文件,但不会刷新数据库的配置。可以输入http://<yourserver>:8080/refresh*来执行刷新。
关于刷新微服务
Spring Cloud配置服务提供了一个基于push的机制——Spring Cloud Bus,每当检测到配置改变后会告诉所有使用这个服务的客户端。Spring Cloud配置需要一个额外的中间件——RabbitMQ。这是一个有效的办法,但并不是所有的Spring Cloud Configuration后端都支持这个机制(如Consul)。
下一章会介绍使用Spring服务发现和Eureka来注册一个服务的所有实例。作者常用的一个方法是,通过写脚本来查询服务发现引擎上某个服务的所有实例,然后立即调用*/refresh*端点。
或者,你可以重启服务器/容器来得到新的配置。如果使用Docker将会很方便。因为重启Docker只需要几秒钟,通过重启就可以重新读取配置数据。
3.4 保护敏感配置信息
在配置文件中全部用纯文本(明文)来保存配置信息的做法不够安全,尤其是当其中含有一些敏感信息,如数据库凭据(credentials)。Spring Cloud Config允许你用对称(共享秘钥)或非对称(公钥、私钥)方式对敏感信息加密。
我们将看看如何搭建Spring Cloud配置服务器以使用对称秘钥的加密。步骤如下:
- 下载安装Oracle JCE
- 创建加密秘钥
- 加密和解密属性
- 配置微服务以在客户端使用加密
3.4.1 下载安装Oracle JCE依赖包
在官网下载好后,定位到文件资源管理器的*$JAVA_HOME/jre/lib/security**目录,将下载好的压缩文件解压,替换对应的local_policy.jar和US_export_policy.jar*文件,若害怕丢失可以先备份一下。
3.4.2 创建一个秘钥
在配置服务器上设置秘钥,可以在bootstrap.yml或者application.yml里。设置encrypt.key: IMSYMMETRIC。秘钥可以随便设置,但是有两点注意:
- 秘钥应为12个字符及以上,最好是随机序列的字符
- 保管好你的秘钥,解密时必须用加密时用的秘钥
3.4.3 加密/解密(property)
现在我们可以对我们希望加密的属性进行加密了。
通过向配置服务器发送POST请求:http://localhost:8888/encrypt,将要加密的对象放在request body中,发送POST请求就能得到加密后的结果。同理,发送/decrypt请求,就能将已加密对象解密。
我们可以将配置文件中的密码替换为我们加密完的结果。
看起来不错!但是仍然存在问题:我们还是能通过GET请求看到密码的明文!向http://localhost:8888/licensingservice/default发送请求,可以看到密码不在原来的位置了(偷偷跑到JSON数据末尾了…)。原因就是,虽然已经将property加密,但是配置服务器会自动将其解密,因此,我们需要将其在客户端解密(客户端在服务端fetch到配置数据,然后将其在客户端解密)。
3.4.4 配置微服务-在客户端解密
- 在服务端配置Spring Cloud Config不要解密
- 在微服务端(licensing server)设置对称秘钥
- 微服务端引入spring-security-rsa依赖
第一步,在配置服务器的application.yml上配置spring.cloud.config.server.encrypt.enables: false。
第二步,在微服务的bootstrap.yml中添加与配置服务器上相同的对称秘钥:encrypt.key: IMSYMMETRIC。
第三步,添加依赖。
现在访问http://localhost:8888/licensingservice/default,发现密码已经是加密过的了。
3.6 小结
Spring Cloud配置服务器让你可以为不同的环境创建不同的配置
Spring使用profiles来自动根据不同环境决定使用什么配置
Spring Cloud配置服务可以使用基于文件/Git的应用来存储应用属性
Spring CLoud配置服务可以使用对称/非对称加密保护你的关键数据
4 发现服务
在分布式架构中,我们需要发现一台机器的物理地址。这个概念随着云计算的出现而出现——服务发现。服务发现可以简单到只用一个配置文件来维护应用程序用到的所有远程地址(服务器),也可以复杂到诸如使用UDDI(Universal Description,Discovery,and Integration)仓库。
服务发现之所以对微服务和基于云的应用这么重要,原因有两个:
第一,有利于应用的快速横向扩展/收缩(scale up/down)。服务消费者通过服务发现将服务的物理地址抽象出来了,由于消费者不知道服务的具体地址,因此可以从服务池(pool)中任意添加/移除新的服务实例。
这也改变了应用架构升级的方式——由升级硬件(垂直扩展)到增加服务器(横向扩展)。
第二,增加了应用的弹性(灵活性)。当服务出现异常(不可用时),服务发现引擎能够快速将它从服务可用列表上移除并寻找可用的服务。应用failure导致的影响被降到了最低。
4.1 我的服务在哪呢?
当你的应用调用位于多台服务器上的资源时,就需要定位这些资源的物理位置。在普通应用(非云架构)中,通常使用DNS+负载均衡器(load balancer)的解决方式。
应用需要调用其他服务时,通过一个DNS名称以及服务所在路径来调用该服务。DNS名称会被解析到一个商用的负载均衡器(硬件,如F5)或者开源的负载均衡器(如HAProxy)。
负载均衡器负责接收请求,检查路由表中托管该服务的服务器,并选择一个服务器,将请求转发(forward)给它。每个服务的实例被部署到一个或多个服务器上,这些服务器的数量是固定的(static),当其中某个服务器挂了(crash),它会被恢复到挂掉之前的状态(与之前有相同的IP和配置)。
为了实现高可用,通常在负载均衡器的基础上再设置一个二级负载均衡器,当负载均衡器挂掉,它会取代他的位置。
上述模型对于一些在固定的服务器上运行的小型应用是可行的,但是对于基于云的微服务应用就不太行了,因为:
单点故障——如果负载均衡器挂了,整个应用就完了!尽管你可以将load balancer做成高可用的(尽管你可以设置二级、三级…),但是负载均衡器往往是应用程序基础设施的集中式阻塞点(centralized checkpoints)。
有限的横向扩展能力——在服务集中到单个负载均衡器集群的条件下,将负载均衡的基础设施扩展到多台服务器上的能力是有限的。许多商用的负载均衡器被两个因素所限制:冗余模型和许可证成本。首先,许多采用热插拔模型,即同一时刻最多有一个负载均衡器在运行。二级负载均衡器只是用来在主负载均衡器失效时才起作用。这样做实际上是被硬件限制了(只能无限提升一台负载均衡器的性能,因为不能多台同时工作);其次,商用负载均衡器具有有限数量的许可证,它面向固定容量模型而不是可变容量模型。
静态管理——大多数负载均衡器并没有快速注册/注销服务的能力。它们使用集中式数据库来存储路由规则,添加新的路由规则也只能通过供应商提供的私有API来实现。
复杂——负载均衡器相当于微服务的代理,消费者的请求需要被映射到物理服务。这就需要定义和部署服务的映射规则(手动)。在传统方案中,新服务实例的注册是手动完成的,并不是在服务启动后立即完成。
这四个原因并不是对负载均衡器的刻意指摘。负载均衡器在企业级环境中工作良好,大多数应用可以通过集中式网络基础设施来处理。此外,负载均衡器仍然可以在集中化SSL终端和管理服务端口安全方面发挥作用。负载均衡器可以锁定位于它后面的所有服务器的入站(入口)端口和出站(出口)端口访问。在满足行业要求方面,如PCI(Payment Card Industry),它仍是一个关键组成部分。
然而,在基于云的世界,你需要处理很多的事务和冗余。中心化的网络结构通常不能胜任。
4.2 云中的服务发现
服务发现机制具有以下特点:
- 高可用——服务发现支持热集群环境,在服务发现集群可以跨多个节点实现共享查找。一个节点不可用时,其他节点可以take over。
- P2P——点对点。每一个节点地位平等,共享服务实例的状态。
- 负载均衡——确保将服务请求合理地分配给不同正在工作状态的服务实例。
- 弹性/灵活性——服务发现客户端应该能够在本地缓存服务信息。本地缓存的意义在于,一旦服务发现引擎不可用,应用仍然能够function。
- 容错性——服务发现需要检测服务实例的健康状态,并对其采取措施。
4.2.1 服务发现架构
怎么实现一个服务发现系统?一般包含以下四个部分:
- 服务注册——怎样将一个服务注册到服务发现代理?
- 客户端查找——客户端查找服务信息(地址)的方式是什么?
- 信息共享——节点之间如何共享服务信息?
- 健康监测——服务们(services)如何将自己的健康状况报告给服务发现代理?
除了依赖**服务发现服务/引擎(service discovery services)**来寻找服务外,客户端也可以通过缓存的方式进行负载均衡。
4.2.2 使用Spring和Netflix Eureka进行服务发现实战
在下面的例子中,我们将许可证(license)服务中包含的组织(organization)相关信息抽出来,放到许可证服务中。当许可证服务被调用时,它将调用组织服务以检索与指定的组织ID相关联的组织信息。组织服务的位置的实际解析存储在服务发现注册表中。
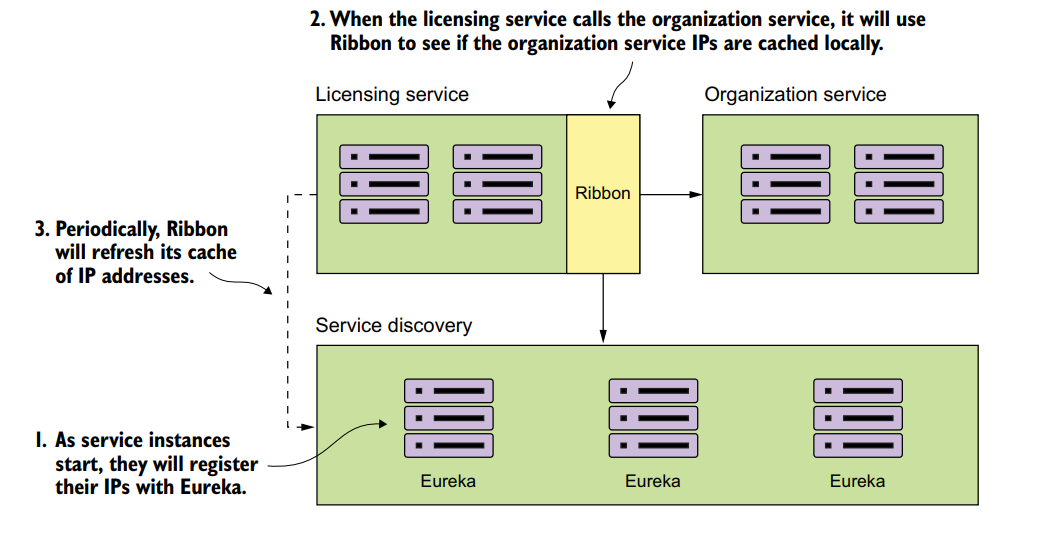
4.3 构建Spring Eureka服务
类似于构建配置服务器(Spring Cloud Config Server)
首先,添加maven依赖:spring-cloud-starter-eureka-server(使用Eureka库,包含Ribbon)。然后在application.yml中添加配置:
1 | server: |
设置Eureka服务器在8761(默认)端口监听;registerWithEureka设为空是因为,Eureka是个用于服务发现的服务器,可以让其它服务到自己这来注册,这个值是为需要通过Eureka注册自己的服务的组件提供的,所以设为false;fetchRegistry设为false是指,不要在本地缓存注册信息,因为这个也是给调用Eureka服务的客户端使用的(从路径也可以看出:eureka.client.*;waitTimeInMsWhenSyncEmpty是指Eureka服务器启动后不会立即宣传已注册的服务,它将等待5分钟,以便所有的服务都注册完成,在本地测试时可以注释掉这行,加快测试过程;单个服务注册Eureka需要最多30s,因为Eureka需要收到来自服务的连续三次心跳ping,每次10s。
最后,在Eureka的启动类中,添加**@EnableEurekaServer**注解,表示启动服务器。
4.4 使用Spring Eureka注册服务
启动了Eureka服务,之后就需要将服务注册到Eureka服务器。
首先,添加依赖:spring-cloud-starter-eureka。
然后,修改需要注册到Eureka的服务的配置文件application.yml。在bootstrap.yml中配置的spring.application.name就作为服务的ID。
1 | eureka: |
eureka.instace.preferIpAddress为true是指用IP来注册服务而不是主机名;registerWithEureka和fetchRegistry都为true,因为这是要注册到Eureka的服务,且开启客户端缓存(每30s,客户端会重新与Eureka通信检查是否需要修改注册服务表);serviceUrl:客户端通过这个地址定位已注册的服务,Eureka的高可用性就是通过这个做到的。可同时配置多个地址(用逗号隔开),当某些服务不可用时,可用服务节点之间会相互通信,保证被路由到合适的服务。
本次注册的是organizationservice,所以配置好后,启动应用,访问http://localhost:8761/eureka/apps/\<APPID>就可以看到已注册的服务的信息。返回的服务状态信息默认是xml格式的,也可以以JSON格式输出(将请求方式改为POST,并把请求头的Accept*值设为application/json*)。
4.5 使用服务发现来查找服务
服务注册完了后,可以进行调用了。我们使用licensingservice来调用organizationservice,调用时不需要知道organizationservice的地址,使用Netflix客户端,服务消费者可以和Ribbon交互。从低到高层次(越高封装越多)的和Ribbon交互的客户端有:
- Spring Discovery client
- Spring Discovery client enabled RestTemplate
- Netflix Feign client
4.5.1 使用Spring DiscoverClient查找服务实例
DiscoveryClient与实际运用
4.5.2 使用Spring RestTemplate(Ribbon-aware)调用服务
4.5.3 使用Netflix Feign客户端调用服务
5 构建客户端弹性模型——Netflix Hystrix
在基于云的环境中,检测出系统组件crash比较容易,检测出组件running slow却很难,因为:
- 服务可能一点一点变坏——服务的崩溃可能由很小的征兆开始,即服务不是一下子就崩溃的。可能开始是一些用户发现了一点问题,直到某一刻突然线程池被耗尽并彻底崩溃。
- 对远程服务的调用通常是同步的,不会缩短调用时间——服务的调用没有超时的概念,开发人员调用服务并等待服务返回(一直)。
- 应用更擅长处理远程资源的彻底故障,而不是部分退化(degradation)——只要没有彻底崩溃,应用会一直调用尽管运行情况很糟糕的服务,直到资源耗尽。
5.1 什么是客户端弹性模型?
客户端弹性模型的目的就是使客户端fail fast。包括:
- 客户端负载均衡模式
- 断路器(circuit breaker)模式
- 后备(fallback)模式
- 舱壁(bulkhead)模式
四个模式之间的配合如下图:
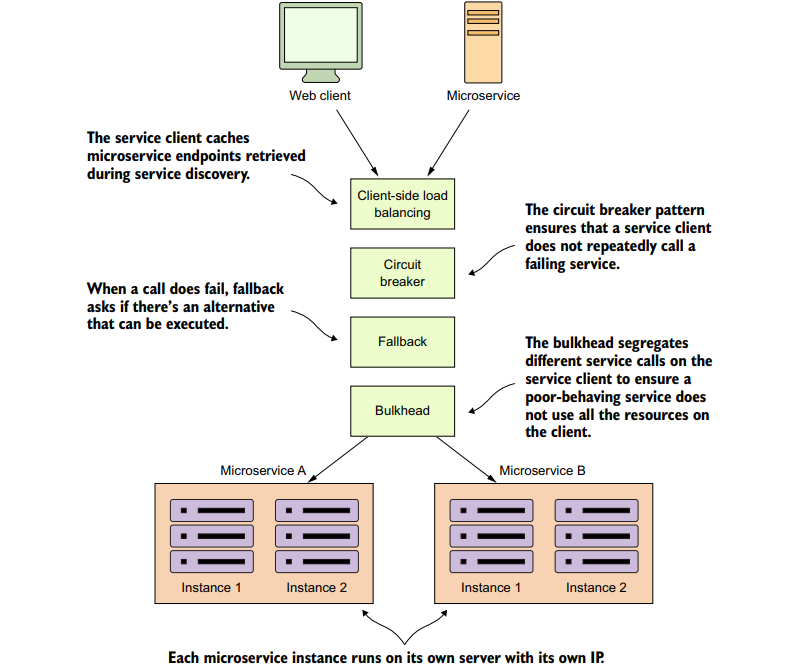
5.1.1 客户端负载均衡
客户端负载均衡要做的事情就是,客户端从服务发现代理(如Netflix Eureka)那里查找服务实例的时候,会将实例的物理地址缓存下来。当服务的消费者(consumer)需要调用服务实例时,客户端load balancer将会从自己维护的一个地址池(service locations pool)中返回一个地址。
客户端负载均衡器是存在于服务客户端和服务消费者之间的,它可以检测服务实例的运行情况。监测到问题后,可以将对应的服务实例从可用服务地址池中移出,阻止对那个服务实例的调用。
这就是Netflix Ribbon库所做的,开箱即用。
5.1.2 断路器模式
断路器模式是模仿电路断路器的工作方式。电路系统中,断路器如果监测到电路中电流过大,会断路,以防止下游部件被烧毁 。
类比过来,软件断路器的作用就是,若调用某个远程服务花费时间过长,断路器就会介入并中断调用。断路器将监视所有对远程资源的调用,如果调用失败次数足够多,断路器就会启动。
5.1.3 后备模式
通过后备模式,当服务失败时,不是立马抛出异常,而是尝试换一个路径执行。这通常涉及从另一个数据源查找数据、将请求排队等待后续处理等。
比如,你的电子商务网站需要监控用户行为并据此做出推荐。通常你可以调用微服务来分析该用户的历史购买行为(记录),并据此做出分析。如果此微服务失败了,那么后备处理可能就是查询“所有”用户的购买记录并分析,这些数据可能来自一个完全不同的服务和数据源。
5.1.4 舱壁模式
舱壁模式基于一个概念——在造船的时候,船舱的设计可以将每个隔间的“危险情况”隔离在内部。当船身破裂,每个船舱还是可以保护行人的(???那Titanic是怎么回事?每个船舱都挂了吗)
同样的概念运用到微服务就是当一个服务要和多个远程资源交互时,使用舱壁模式,你可以将对不同远程资源的调用分离到不同的线程池,来降低风险。某个服务响应速度变慢,处理同类型服务调用的线程池将变得饱和,不再接收请求。
5.2 为什么客户端弹性很重要?
简而言之,就是当A服务调用B服务,B服务又调用C服务…很多个服务调用形成了一条链,一旦被很多服务调用的“源头”出现问题,就可能会导致后面很多服务的崩溃。
当服务B发现服务C响应缓慢时,断路器会设置一个timer来检测请求被处理的时间,若计时器超时后服务B还没有得到响应,就会收到一个error,并且断路器开始记录error的个数;如果一段时间内error次数过多,所有调用服务C的请求都会直接被拒绝(强行fail)。
当被断路器强行插手解决问题时,有三个好处:
- B服务知道前方有问题了,不需要再等断路器的超时通知了
- B服务可以决定自己是fail还是另寻出路(后备模式)
- 给了服务C一点时间和空间去恢复自己
断路器的存在使得远程调用可以:
- Fail fast——防止事情进一步恶化
- Fail gracefully——断路器使得应用开发者们可以在意外发生时另寻他法,如从其他数据源检索数据
- Recover seamlessly——断路器可以负责查询资源是否可用,服务是否恢复,并开发访问接口
5.3 使用Hystrix
构建和实现断路器模式、后备模式和舱壁模式,需要对线程和线程管理有很深的理解。Netflix的Hystrix库在微服务架构中久经考验,你可以使用它构建强大的客户端弹性模型。需要做的包括:
- 在licensingservice的pom.xml中添加Spring Cloud/Hystrix依赖。
- 使用Spring Cloud/Hystrix标记(annotations)来将远程调用包装成断路器模式。
- 为每一个远程资源-断路器定制超时时间。可以设定一个断路器强行接管控制之前,failure的次数。
- 为服务设计后备模式策略(fallback strategy),以在断路器生效时起作用。
- 为每个远程调用设立单独的线程池,并使用舱壁模式将不同的远程资源隔离开,
5.4 配置licensing服务器
在licensingservice的pom.xml中添加spring-cloud-starter-hystrix和hystrix-javanica,并制定hystrix-javanica的版本为1.5.9。实际上,spring-cloud-starter-hystrix中以及包含了hystrix-javanica,但是Cmamden.SR5版本的Spring Cloud包含的是1.5.6的hystrix-javanica,其中的一个问题是:如果Hystrix代码没有后备,会跑出一个java.lang.reflect.UndeclaredThrowableException异常而不是com.netflix.
hystrix.exception.HystrixRuntimeException,于是单独声明一下后者的版本,从maven拉取一个不同版本的包。
然后在需要使用断路器模式的服务的启动类上加上注解**@EnableCircutBreaker**就行了。
5.5 使用Hystrix实现一个断路器
我们将看到两大类的Hystrix实现:对数据库的调用和内部服务调用。如图:
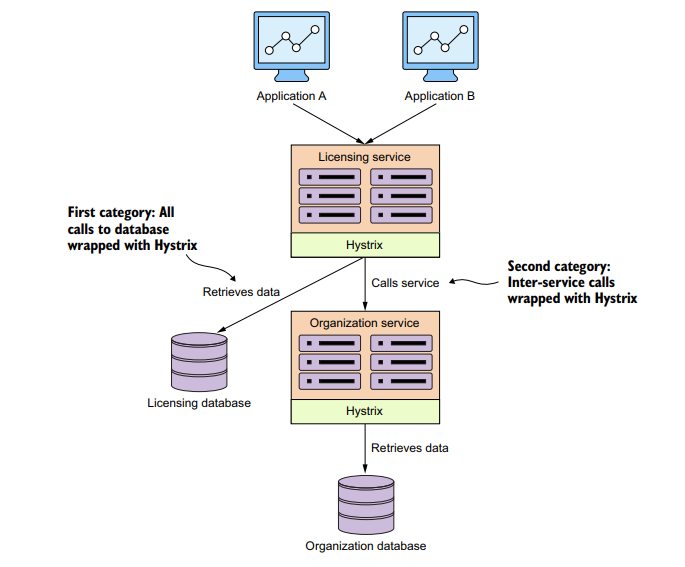
两种类型调用中,Hystrix的使用是类似的。
首先,看一下如何使用一个同步的Hystrix断路器来控制从licensing数据库检索licensing服务的数据。通过同步方式调用,许可证服务将会检索数据,同时它会等到SQL语句执行完成,或者断路器提示超时。
通过添加*@HystrixCommand*注解,方法被标记为一个Hystrix断路器,Spring框架会为其生成一个动态代理,将所有调用此方法的请求放到一个线程池中处理。尽管看起来没有写多少代码,但是可以实现很多功能。断路器会中断任何超过1000ms的调用。
因为我是在本地启动的数据库,所以如果数据库没问题,可能断路器一直不需要工作。因此,在方法中加入一些【人工延迟】,来模拟响应缓慢的情况。
1 | private void randomlyRunLong() { |
使用一个随机数(取值【0|1|2】+1),当值为3时,线程休眠11000ms。sleep()方法如下:
1 | private void sleep(){ |
现在访问http://localhost:8082/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a/licenses/,多刷新几次,会发现出现了超时错误,这就说明我们的断路器起作用了,由于数据库操作超时导致抛出了*com.netflix.
hystrix.exception.HystrixRuntimeException*异常。

5.5.1 对organizationservice的调用超时
使用方法级的标记(断路器)的好处就是,它不区分你是在访问数据库还是调用另一个微服务。
注意
使用*@HystrixCommand标记尽管很容易,但是使用默认的标记可能有问题。因为默认的标记会将所有的远程调用放到同一个线程池中,下面的章节实现了舱壁模式,其中自定义了@HystrixCommand*标记的一些参数。
5.5.2 定制断路器的超时时间
定制断路器的超时时间,只需要在*@HystrixCommand*标记上增加对应的参数timeoutInMilliseconds即可,如下:
1 |
|
commandProperties中可以添加很多@HystrixProperty,每一个属性由一个name和一个value构成。
类似commandProperties,也可以设置threadPoolProterties的参数。
关于服务超时
显然,12s的断路器超时只是我用来作为教学的例子。在分布式环境中,如果我听到开发团队反馈,说远程服务调用上的1s超时时间太少了,因为他们的服务平均需要5-6s的时间,那么我会经常感到紧张。
这些反馈通常告诉我,被调用的服务存在为解决的性能问题。开发人员应该避免在Hystrix调用上增加默认超时时间的诱惑,除非实在无法解决运行缓慢的服务调用。
如果确实遇到一些比其他服务调用需要更长时间的服务调用,务必将这些服务调用隔离到单独的线程池中。
5.6 后备处理(fallback)
断路器模式的【美妙之处】在于,中间商是可以赚差价的
嗯??其实就是,远程资源的消费者和其本身之间存在一个中介,每当有请求,中介会拦截下来,为你选择最安全、效率最高的服务;当出现异常情况,中介也可以选择一个备用方法来执行(前提是你写了备用方法,因为它只有使用fallback的机制,但没有创造fallback的机制)。
1 | @HystrixCommand(fallbackMethod = "buildFallbackLicenseList") |
在“正常工作”的方法上添加HystrixCommand标记,并设置其fallbackMethod,并在下方写上fallback方法实现,且两个方法的返回值和参数需相同。当服务无法正常工作时,会调用fallback方法处理。
现在,连续调用几次licensingservice服务,请求超时时会由fallback方法处理:
5.7 实现舱壁模式
在@HystrixCommand标记中添加参数:threadPoolKey、threadPoolProperties
threadPoolKey是说为指定的方法建立一个新的Hystrix线程池来处理。
threadPoolProperties可以配置两个参数,name="coreSize", value="30"指定线程池大小;name="maxQueueSize", value="10"指定队列中线程数量,即当线程池满时可以排队等待的请求数量;
5.8 基础进阶——微调Hystrix
至此,我们已经学会了如何使用Hystrix实现断路器和舱壁模式。接下来我们要对断路器的行为进行定制化微调(customize)(通过修改参数,使Hystrix的工作模式更符合我们的实际情况)。记住,Hystrix能做的不只是将长时间的远程调用设为超时,Hystrix还可以监控调用失败的次数。当一个服务调用失败次数过多,Hystrix会自动阻止来自远程的调用(即请求无法到达远程资源)。
这样做(failing fast)有两个好处:1. 客户端不会一直调用并等待超时信号发出;2. 服务端不会很快挂掉,有一个恢复时间。
每当一个Hystrix命令遇到服务错误时,它会启动一个10s的计时器,来检查服务失败的频率。10s的窗口大小是可配置的。首先Hystrix会检查10s内发生了几次调用,如果调用次数少于窗口内可以发生调用次数的最小值,那么及时这些调用全部失败,Hystrix也不会fail fast(自动阻止来自远程的调用)。例如,10s内Hystrix会执行fail fast的默认调用次数为20,那么如果10s内有15个调用都失败了,Hystrix不会启动fail fast,调用仍会到达远程服务。
如果远程调用的失败次数在10s内达到最小值后,Hystrix将会查看整体故障的百分比。如果比例超过了阈值(默认50%),Hystrix将对所有远程调用触发断路器并让其失效。同时,它会在此过程中,不断试探故障是否恢复,通过定时开闸的方式。即,它会开启一个新的活动窗口,每5s它会让一个请求通过,如果请求成功,则Hystrix会重置断路器,放开请求通道;否则,过5s继续尝试。
因此,我们可以通过以下参数来控制我们的断路器工作效果。
1 |
requestVolumeThreshold:Hystrix将断路器断闸之前,10s内接收到的连续的调用个数
errorThresholdPercentage:整体调用失败(由于超时、抛出异常或返回HTTP 500)的百分比。超过后Hystrix会执行fail fast。
sleepWindowInMilliseconds:断路器跳闸之后,Hystrix允许另一个调用通过以便查看是否恢复健康之前Hystrix的休眠时间。
timeInMilliseconds:监视服务调用情况的窗口大小。
numBuckets:统计窗口中失败次数的数据。Hystrix将统计数据放到bucket中,以此判断调用是否失败。timeInMilliseconds的值必须能被numBuckets整除,如timeInMilliseconds为15000(15s)的同时numBuckets为3或5。
检查失败次数的统计窗口越小且bucket数量越多,月耗费CPU和内存资源。因此,要酌情设计窗口大小和bucket数量。
5.8.1 重新审视Hystrix配置
配置Hystrix时,可以设置不同的级别(level):
- 应用程序级别的默认值
- 类级别的默认值
- 在类中定义的线程池级别
通过在类级别设置默认参数,可以是类中所有Hystrix命令享有相同的配置。类级别属性通过**@DefaultProperties**的类级注解设置。除非希望在某线程池上显示地覆盖,否则所有线程池都将继承应用程序级别的默认设置或类中定义的默认设置。
5.9 线程上下文和Hystrix
当一个*@HystrixCommand*被执行时,它可以使用两种不同的隔离策略来运行:THREAD和SEMAPHORE。默认使用THREAD方式。使用线程方式隔离,Hystrix命令可以将调用格力在一个线程池中运行,不会将它的上下文和调用它的父线程共享。这样Hystrix可以随时中断线程的执行,不必担心会影响到调用它的父线程。
使用基于信号量的隔离方式,Hystrix管理由@HystrixCommand注解保护的分布式调用,不需要启动新线程,若调用超时,就会中断父线程。在同步容器服务器环境(Tomcat)中,中断父线程将会导致开发人员无法捕获异常。
要设置隔离方式,可以在commandProperties参数中添加@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")。
注意:
默认情况下,推荐使用THREAD隔离方式。这使你和父进程间保持了一个高层次的隔离。THREAD方式比SEMOPHORE方式更重,SEMOPHORE更轻量级。SEMOPHORE更适合服务量很大且使用异步I/O编程模型(如Netty)运行的情况。
5.9.1 ThreadLocal和Hystrix
Hystrix在默认情况下不会将父级的上下文传递到由Hystrix命令管理的线程中。如,父线程中的ThreadLocal值在被此线程调用的线程(子线程,且使用@HystrixCommand标记)的方法中不能使用(默认隔离方式为THREAD情况时)。
举个例子说明。通常在一个基于REST的环境中,你想给某个服务调用传递一个上下文信息,以便于管理这个服务。比如,可以在HTTP请求头传递一个关联ID(correlationID)或者认证token,可以在下游所有的服务中调用。关联ID是唯一标识符,可用于在单个事务中跨多个服务调用进行追踪。
要在所有服务调用中使用这个值,可以用一个Spring Filter类来拦截所有调用该REST服务的请求,从HTTP请求头中检索该信息,并将之存储到自定义的UserContext对象中。这样,在任何REST服务调用中要使用这个值时,可以从ThreadLocal存储变量中检索UserContext并读取其值。以下代码展示了如何在licensingservice中使用过滤器。
1 |
|
UserContextHolder类用来在ThreadLocal中存储UserContext。一旦存储在ThreadLocal中,任何为请求执行的代码都会使用存储在UserContextHolder中的UserContext对象。UserContextHolder类如下:
1 | public class UserContextHolder { |
现在可以在许可证服务中添加一些日志了,以便测试。
- 在/licenses/utils/UserContextFilter.java中的doFilter()方法
- /licenses/controllers/LicenseServiceController.java中的getLicenses()方法
- /licenses/services/LicenseService.java中的getLicenseByOrg()方法,此方法是使用@HystrixCommand标记的
现在可以在调用license服务时加上一个HTTP header:
| key | |
|---|---|
| tmx-correlation-id | TEST-CORRELATION-ID |
UserContextFilter Correlation id: TEST-CORRELATION-ID
LicenseServiceController Correlation id: TEST-CORRELATION-ID
LicenseService.getLicensesByOrg Correlation id:
可以看到,由@HystrixCommand标记的方法*LicenseService.getLicensesByOrg()*没有打印出correlationID,这是因为它没有找到当前线程的UserContext。我们可以通过Spring Cloud和Hystrix提供的并发策略机制来实现上下文的传递。
5.9.2 HystrixConcurrencyStrategy实战
Hystrix允许你定义自己的并发策略来包装你的Hystrix调用,并将父线程的上下文注入到有Hystrix命令管理的子线程中。实现HystrixConcurrencyStrategy,你需要做以下三件事:
- 定义自己的Hystrix并发策略类
- 定义一个Java Callable类,将UserContext注入Hystrix命令中
- 配置Spring Cloud来使用自定义的Hystrix并发策略
自定义Hystrix并发策略类
Hystrix只允许你为一个应用定义一个并发策略。Spring Cloud已经定义好了一个并发策略,用来处理Spring security的信息。你可以将自己定义的并发策略和Spring Cloud提供的集成到一起,作为Hystrix并发策略。
我们通过ThreadLocalAwareStrategy.java来实现
1 | public class ThreadLocalAwareStrategy extends HystrixConcurrencyStrategy{ |
定义一个并发策略类,继承HystrixConcurrencyStrategy,Spring Cloud已经有了一个并发策略类,所以构造方法中需要传入现有的currency strategy。在wrapCallable()**方法中,传入一个Callable变量,DelegatingUserContextCallable**方法负责将父线程(执行REST服务调用的线程)的UserContext传入Hystrix命令标记的方法中。
定义一个Java Callable类来将UserContext注入Hystrix命令
接下来就是实现如何将父线程的context传入Hystrix命令中。通过DelegatingUserContextCallable.java实现。
1 | public final class DelegatingUserContextCallable<V> implements Callable<V> { |
可以看到,DelegatingUserContextCallable类包含一个Callable对象(用来调用有*@HystrixCommand标记的方法),一个UserContext对象(用来保存从父线程传入的UserContext)。设置好UserContext,存储UserContext的ThreadLocal变量就和有Hystrix标记的线程关联起来了。下面try{}中的call方法只是一个模板,实际使用时改成相应的代码(即有Hystrix标记的方法,如**LicenseServer.getLicenseByOrg()***)。
配置Spring Cloud来使用你自己的Hystrix并发策略
定义好了Hystrix并发策略和线程上下文传递方法,我们需要将它们告诉Spring Cloud和Hystrix。为此,我们新建一个配置类ThreadLocalConfiguration。
1 |
|
@Autowired:当配置类对象被构造时,它将会autowire(自动装配)现有的HystrixConcurrencyStrategy。
注册自己的并发策略前,先拿到所有的Hystrix组件(如**getEventNotifier()**);重置;然后注册自己的并发策略并将组件添加进去。最关键的一句,注册自己的并发策略——HystrixPlugins.getInstance().registerConcurrencyStrategy(new ThreadLocalAwareStrategy(existingConcurrencyStrategy));
现在,重新构建并重启服务,通过GET请求访问 http://localhost:8081/v1/organizations/e254f8c-c442-4ebe-a82ae2fc1d1ff78a/licenses/ ,会发现被@HystrixCommand标记的方法也成功地找到了【TEST-CORRELATION-ID】 ,表明UserContext成功由父线程(调用服务的线程)传入被Hystrix标记的线程。
打印出的日志信息:
UserContextFilter Correlation id: TEST-CORRELATION-ID
LicenseServiceController Correlation id: TEST-CORRELATION-ID
LicenseService.getLicensesByOrg Correlation id: TEST-CORRELATION-ID
6 服务路由——Zuul
在分布式架构(如微服务)中,你需要确保安全(security)、日志(logging)、用户追踪(tracking of users)这样的活动在多个服务调用中能够正常发生,并且尽量在所有服务中一致的实现这些特性,而不需要每个开发团队构建自己的解决方法。尽管可以使用公共库或框架来在单个服务中构建这些功能,但这样做有三个影响:
第一,在构建的每个服务中很难始终实现这些功能。开发人员专注于交付功能,在每日的快速开发工作中,他们很容易忘记实现服务日志或跟踪。尤其是对于那些在金融服务或医疗保健等严格监管的行业工作的人来说,一致且用文档来记录系统中的行为通常是符合政府法规的要求。
第二,正确地发现这些功能是一个挑战。对每个正在开发的服务进行诸如微服务安全的建立与配置可能是很痛苦的。将实现cross-cutting关注点(如安全问题)的责任推给下面的开发团队将会增加开发人员忘记实现或没有正确实现这些功能的可能性。
第三,这将会在所有服务中创建一个hard dependency。在所有服务中共享的公共框架中创建的功能越多,想要添加/更改功能就越困难,往往需要重写编译、部署。共享库中的核心功能的升级可能成为一个数月的迁移过程。
为了解决这个问题,将这些横切关注点(cross-cutting concerning)抽象成一个独立的且作为应用程序中所有服务调用的过滤器和路由器的服务很有必要。这种横切关注的叫做服务网关。服务客户端不再直接调用服务,而是通过服务网关(作为单个策略执行点(Policy Enforcement Point,PEP)),进行路由,到达最终目的地。
本章,使用Spring Cloud和Zuul来实现服务网关。要实现的有:
- 把所有服务调用放到一个唯一的URL后,将调用请求做映射(通过服务发现机制)
- 把correlation ID注入到每个经过服务网关的服务中
- 把correlation ID注入到从客户端发回的响应中
- 构建一个动态路由机制,将具体的organizations服务(被调用服务)路由到某个不同的服务实例端点(负载均衡)
6.1 服务网关是什么
目前为止,我们已经会用两种方式调用服务了——web client或服务发现引擎(如Eureka)
服务网关存在于服务客户端与服务之间,作为调用服务时的统一中间件。
可以在服务网关中实现的横切关注点(每个/多数服务都要用的)有:
- 静态路由——通过统一URL调用服务,不必知道每个服务的具体端点(一般需要知道服务名)
- 动态路由——根据请求/数据的不同,动态的进行路由。如,参与测试版(beta)程序的客户可能会被路由到特定服务集群的服务,与正常版不同。
- 认证、授权——因为所有服务调用都要通过网关,所以在这里做认证/授权很方便,验证服务调用者是否经过认证,并有权限调用相应服务。
- 度量数据收集和日志记录——网关可以收集度量数据和日志信息当服务调用经过时,还可以确保在用户请求上提供关键信息以确保日志统一。这并不意味着不需要从单个服务中收集度量数据,而是通过服务网关可以集中收集许多基本度量数据,如服务调用次数和服务响应时间。
且慢——服务网关不会造成单点故障吗?
前面说过,集中式负载均衡器会造成单点故障和性能瓶颈,若没有正确实现,服务网关也会有同样风险。因此要记住一下几点:
在单独的服务组前面,负载均衡器仍然很有用。
要保持为服务网关编写的代码是无状态的。
要保持为服务网关编写的代码是轻量的。
6.2 Spring Cloud和Netflix Zuul
要使用Zuul,首先要做一些准备工作:
- 引入依赖
- 修改项目代码,将服务加上合适的标记以表明它是一个Zuul服务
- 配置Zuul来和Eureka通信(可选)
注意:第三点中,若使用了服务发现引擎,则请求来到服务网关后,服务网关还需要“查表”(与服务发现引擎通信),才能知道具体的服务实例端点。
6.2.1 构建Zuul项目
即构建一个Zuul服务器,用来作服务网关。首先添加依赖spring-cloud-starter-zuul
6.2.2 为Zuul服务使用Spring Cloud注解
在zuulsvr这个module中新建启动类,并增加*@EnableZuulProxy*注解,使服务成为一个服务器。
注意:
如果你开启了自动补全(IDE),你可能注意到还有一个注解叫*@EnableZuulServer。两者的区别就是@EnableZuulServer不会加载Zuul反向代理过滤器,以及Eureka服务器用来服务发现。换句话说,@EnableZuulProxy*预置好了更多的过滤器,如果你想用现成的,那就拿来直接用。如果你不想用Eureka来实现服务发现(如Consul),你可以选择Server。
6.2.3 配置Zuul与Eureka进行通信
Zuul默认可以和Spring Cloud的相关组件进行合作。如,Zuul会自动使用Eureka来作为服务发现服务器,使用Ribbon来进行客户端请求的负载均衡。
在Zuul的application.yml中添加Eureka的配置即可,与Eureka中的相同。
1 | eureka: |
6.3 在Zuul中配置路由
Zuul核心就是一个反向代理。反向代理就是一个中间的服务器,处于客户端(想要访问某资源)和资源之间。客户端不知道它访问的是服务器还是代理。反向代理服务器就像真正的服务器那样,处理客户端请求。
关于映射路由,Zuul有多种机制:
- 通过服务发现自动映射
- 通过服务发现手动映射
- 通过静态路由手动映射
6.3.1 通过服务发现自动映射路由
路由映射规则可以在application.yml中定义。其实,也可以不用定义。Zuul可以根据服务ID自动进行路由(0配置!)。比如,想调用organizationservice,你可以通过调用Zuul服务实例,访问端点:http://localhost:5555/organizationservice/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a。
使用Zuul集成Eureka的好处是,你永远都只需要知道单一的URL端点(Zuul),你可以在不告知Zuul的情况下添加/移除服务。因为Zuul总是和Eureka通信,来获得每个服务的物理地址。
使用**/routes**端点可以查看由Zuul管理的路由:http://localhost:5555/routes。

右边是服务ID(名),左边是Zuul创建的路由URL
6.3.2 使用服务发现手动映射路由
Zuul允许你手动的定义路由映射规则。默认情况,Zuul通过服务ID(如organizationservice)来映射,如果你想使用自己的规则,可以在Zuul服务的application.yml中添加如下配置:
1 | zuul: |
现在就可以通过http://localhost:5555/organization/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a访问到organization服务了。再次访问http://localhost:5555/routes,会发现映射到organizationservice的有两个路由:`"organization/**": “organizationservice”;“organizationservice/**”: “organizationservice”。其中,第二个是Zuul自动生成的,第一个是刚才我们配置的。如果不需要Zuul为我们自动生成,可以使用**ignored-services**来配置,如:ignored-services: ‘organizationservice’`。如果想把所有Zuul生成的都忽略掉,使用*****。
一个用来区分【API路由】和【内容路由】常见的方法是,所有的API路由以**/api打头。对于Zuul, 可以在配置项中加上/prefix**。就像下面这样:
1 | zuul: |
6.3.3 使用静态URL手动路由
Zuul可以用来路由一些不是由Eureka管理的服务。假如你的licensing service是由Python写的,你想用Zuul来做服务代理,可以直接在配置文件中写死:
1 | : /licensestatic/** |
这样,对于licensestatic端点,Eureka不会知道,所有访问到licensestatic的请求会直接被路由到http://licenseservice-static:8081端点。这样做存在一个问题:绕过了Eureka,只有一条路径可以用来处理请求(即licensestatic.url)。幸运的是,可以手动配置Zuul来禁用Ribbon和Eureka集成,然后列出Ribbon将进行负载均衡的各个服务实例。如下面所示:
1 | zuul: |
处理非JVM服务
使用静态路由并在Ribbon中禁用Eureka的一个问题是,禁用了通过Zuul网关的素有服务的Ribbon支持。这意味着Eureka服务器的压力会更大,因为Zuul不能使用Ribbon来缓存查找服务。Ribbon做的就是客户端负载均衡,即每次查找不是直接问Eureka,它会先在本地查找缓存,并定期和Eureka通信来将最近使用到的缓存到客户端。如果不能使用Ribbon,那么每次Zuul都会直接调用Eureka来解析服务地址。
因此,我们可以使用多个服务网关,基于不同的需求。对于非JVM的应用,可以设置一个单独的服务器来处理。作者推荐,最好是使用Spring Cloud “SideCar”实例。使用SideCar你可以用一个Eureka实例注册一个非JVM服务,并通过Zuul进行代理。有兴趣可以在http://cloud.spring.io/spring-cloud-netflix/spring-cloud-netflix.html#spring-cloud-ribbonwithout-eureka上看看。
6.3.4 动态重新加载路由配置
Zuul暴露了一个【基于POST】的路由:**/refresh**。通过访问/refresh端点,就可以刷新配置信息。
为什么没有刷新??在Zuul的application.yml和配置服务器上分别改都没用…
6.3.5 Zuul和服务超时
Zuul使用Netflix的Hystrix和Ribbon库来防止“又臭又长”的服务调用影响服务网关的性能。默认情况下,Zuul会终止并返回HTTP 500错误,对于任何超过1s的调用(这也是Hystrix的默认值)。可以在Zuul服务的配置文件中直接更改此配置值:
1 | : 2500 |
如果你想将某个服务的超时时间设置的不一样,而不是对所有服务生效,把default部分改成相应服务ID就好了。如,设置licensingservice的超时时间为3s:
1 | : 3000 |
然而,尽管我们可以设置自己的超时时间(其实设置的是Hystrix的超时时间),Ribbon也有一个超时时间,默认为5s。万一自己设计的服务有超过5s的调用请求的风险,最好还是设置一下这个:
1 | : 7000 |
即,**若有需要配置超时时间≥5的,需要同时配置Hystrix和Ribbon**。
6.4 Zuul的强大之处——过滤器
除了代理所有请求,简化服务调用,Zuul真正厉害的地方应该在于需要通过网关流经所有的服务调用的自定义逻辑。这种自定义逻辑通常用于强制执行一组一致性的应用程序策略,如安全性、日志记录和对所有服务的跟踪。
这些策略也被叫做“横切关注点(cross-cutting concerns)”,因为要将它们应用在所有服务中。这样,可以按照J2EE中的servlet过滤器或Spring Aspect类似的方式来使用。servlet过滤器或Spring Aspect被本地化为特定的服务,而使用Zuul和Zuul过滤器可以为通过Zuul路由的所有服务实现横切关注点。
Zuul允许你在Zuul网关内使用过滤器来构建自定义逻辑。Zuul支持的过滤器有:
- 前置过滤器——在Zuul将实际请求发送到目的地之前被调用。前置过滤器通常执行确保服务具有一致的消息格式(如,HTTP首部是否设置妥当)的任务;或者确保调用服务的用户已通过验证和授权(Authentication、Authorization)。
- 后置过滤器——在目标服务被调用并将响应发送回客户端后被调用。通常用来记录从目标服务返回的响应、处理错误或审核对敏感信息的响应。
- 路由过滤器——在调用目标服务之前拦截调用。通常用来确定是否需要进行某些级别的动态路由。例如,本章后面使用的路由级别的过滤器,将在同一服务的两个不同版本之间进行路由,以便将一小部分的服务调用路由到服务的新版本。这样就能在不让每个人都使用新服务的情况下,让少量的用户体验新功能。
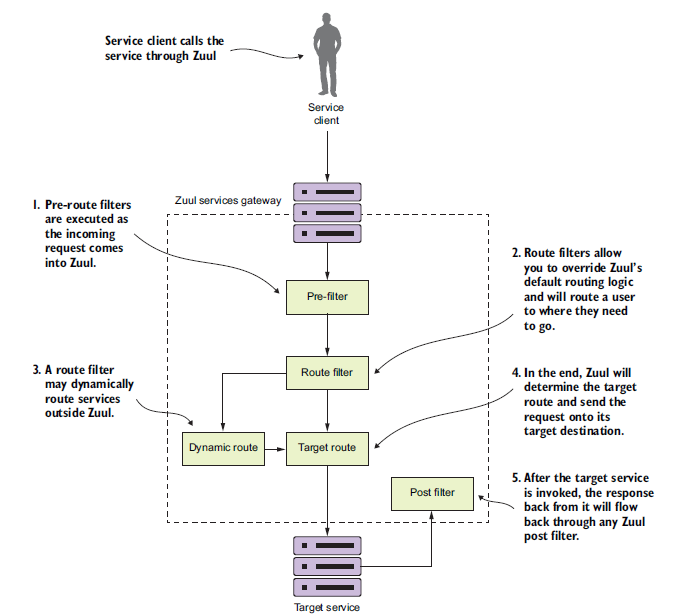
上图为三层过滤器的原理。、

上图为结合应用的三层过滤器实现:
- TrackingFilter:检查请求的HTTP首部,若不存在correlationID(关联ID),则为其创建一个。
- SpecialRoutesFilter:确定是否需要动态路由,即是否需要将一部分满足某种条件的请求路由到同一个服务的另一个版本上。如,确定是否需要做A/B测试。A/B测试是指给用户呈现同一个服务的两个不同版本,在投放到用户群体前,可以测试版本中新的feature。
- ResponseFilter:确保响应中有correlationID。
6.5 构建前置过滤器 | 产生关联ID
创建一个类:TrackingFilter。它会检查所有请求,确保请求头中都有一个header:tmx-correlation-id。此ID可以用来在多个服务中跟踪某个用户的请求。关联ID的实现将使用ThreadLocal变量。
如果某个请求的HTTP首部没有tmx-correlation-id,Zuul下的TrackingFilter类会生成并设置好关联ID。关联ID代表着某次服务调用是为了执行用户的某个请求而做的一系列服务调用的一部分。
接下来分析TrackingFilter类。
所有的Zuul过滤器都要继承ZuulFilter类,并重写四个方法:filterType()、filterOrder()、shouldFilter()、run()。
注意
对于普通的Spring MVC或者Spring Boot服务,RequestContext是从*org.springframework.web.servletsupport.RequestContext**包中引入的;而在Zuul中,提供了一个额外的RequestContext,以方便进行Zuul相关的操作,即它是来自com.netflix.zuul.context***包的。
6.5.1 在服务调用中使用关联ID
我们将关联ID加入了流经Zuul的每个服务调用中,但是要怎么保证:
- 关联ID可以被正在被调用的服务访问
- 所有调用此服务的下游服务调用仍然可以将关联ID继续往下传递
实现过程入下:
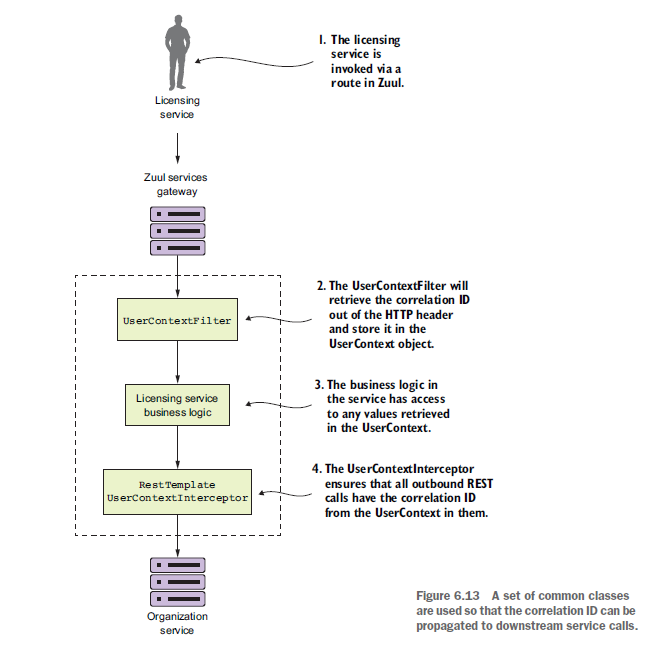
以上过程发生了四件事:
- 当服务调用(licensing service)经过Zuul网关时,TrackingFilter将会把关联ID注入所有经过Zuul的请求头中。
- UserContextFilter类是一个自定义的HTTP ServletFilter。它将一个关联ID和一个UserContext类对象关联起来(根据关联ID创建一个UserContext)。UserContext对象用于将一些待会要用到的值存储到ThreadLocal中。
- 许可证服务的业务逻辑要执行一个对组织服务的调用。
- RestTemplate类用来调用组织服务。RestTemplate类将使用一个自定义的Spring Interceptor(UserContextInterceptor 拦截器)类,来将关联ID注入返回的响应请求的HTTP首部中。
重复代码与共享库对比
是否应该在微服务中使用公共库的话题时微服务设计中的一个灰色地带。微服务纯粹主义者会说,不要在服务中使用自定义框架,因为它会在服务中引入人为的依赖,业务逻辑的更改或bug修正可能对所有服务造成大规模的重构。但是,其他一些微服务实践者指出,这样是不切实际的,因为存在一些情况(如UserContextFilter),构建公共库并在服务之间共享它是有意义的。
当我们在处理一些基础设施风格的任务时(所有服务都要用的那种),很适合使用公共库;若是共享面向业务的类,那就是自找麻烦,因为这样是在打破服务之间的界限。
在本章示例代码中,作者之所以在每一个服务的utils包中都写了UserContext、UserContextFilter、UserContextInterceptor类的副本,因为这样不需要创建一个共享库并把它发布到Maven上然后引入依赖,这样会看起来更复杂。
UserContextHolder:存储UserContext
UserContextHolder负责将UserContext存储到一个ThreadLocal变量中,以便于让处理当前请求的线程所调用的方法能够访问。
自定义RestTemplate和UserContextInteceptor类:保证关联ID向下游传播
要使用UserContextInteceptor,需要定义一个RestTemplate类,并把UserContextInteceptor放到里面。如下:
1 |
|
@LoadBalanced注解表示这个RestTemplate对象要使用Ribbon;将UserContextInteceptor加入到创建好的RestTemplate中。经过这样定义,每当你使用**@Autowired**标记,将RestTemplate注入一个类中,创建的RestTemplate都是带有UserContextInterceptor的。
日志聚合、认证…
现在有了关联ID,并可以把它传递到每个服务上,那就可以跟踪一个事务啦。可以考虑将所有服务日志放到一个中心的日志聚合处,每个条目通过关联ID来标识,第九章介绍的Spring Cloud Sleuth就是做这个的。
6.6 构建后置过滤器 | 接收关联ID
与构建前置过滤器类似,构建一个ResponseFilter,用于将关联ID”输出“到返回的响应中。
6.7 构建动态路由过滤器
目标:动态过滤器可以获取到所有经过Zuul的服务ID,然后调用SpecialRoutesService,SpecialRoutesFilter会产生一个随机数作为权重,通过与新版本的服务进行比较,决定是否进行特殊路由。
6.7.1 构建路由过滤器的框架结构
还是像之前一样,继承ZuulFilter并覆盖其方法。
1 |
|
6.7.2 实现run()方法
1 |
|
首先,调用SpecialRoutesService服务来检查是否存在关于这个服务(如service_name=organizationservice)的一个特殊路由记录。
useSpecialRoute方法会将在数据库中查到的weight值与生成的随机值的大小做比较,决定是否将请求路由到备用服务。
如果调用特殊路由服务找到了一条记录,则为其构建一个完整的URL。
最后,forwardToSpecialRoute方法将请求转发。
6.7.3 转发路由
6.7.4 整合
7 保护你的微服务(Securing)
本章主要使用Spring Cloud security和OAuth2来保护基于Spring的服务。OAuth2是一个基于令牌(token)的安全框架,允许用户使用第三方验证服务进行验证。如果用户成功进行了验证,则会出示一个令牌,该令牌必须与每个请求一起发送。然后,验证服务可以对令牌进行确认。使用OAuth2的好处是,在调用多个服务来完成用户请求时,用户不需要在处理请求的时候为每个服务都提供自己的凭据信息就能完成验证。
一个成熟的OAuth2实现还需要一个前端Web应用程序来输入用户凭据。本章将使用REST客户端(如POSTMAN)来模拟凭据的提交。有关如何配置前端应用程序,可以参考:https://spring.io/blog/2015/02/03/sso-with-oauth2-angular-js-and-springsecurity-part-v。
首先,来看一下OAuth2架构:
7.1 OAuth2简介
OAuth2安全框架包含四个组件:
- 被保护的资源——既然要认证用户才能访问,那么资源/微服务就是被保护的。
- 资源所有者——资源所有者定义了应用的名字,可以访问的用户,可访问用户的权限。每个通过资源所有者注册的应用都有一个应用名和应用秘钥。此两者是证书的一部分。
- 应用——指的是调用服务的应用,即用户通过此应用来调用某个服务。
- OAuth2认证服务器——认证服务器是存在于应用和服务之间的中介。有了认证服务器,用户不必每次都使用证书来验证身份。
工作流程如下:
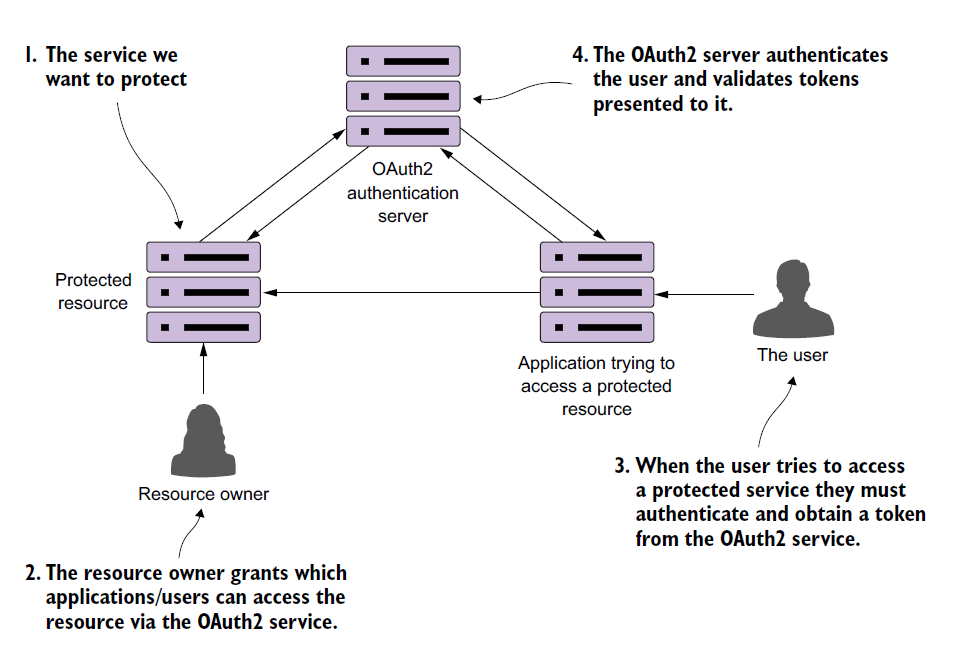
如上图所示,每次验证身份时只需要通过token即可。
资源拥有者,可以使用OAuth2和角色来定义用户可以访问的服务端点以及可以使用的HTTP动词(GET、POST等)。
Web服务安全是一个很复杂的主题。你要明白是谁在调用你的服务:(内部用户;外部用户),怎样调用(内部基于Web的客户端;移动设备;外部的Web应用),有哪些行为。OAuth2允许你使用以下四种授权方式:
- 密码(password)
- 客户端证书(client credential)
- 授权码(authorization code)
- 隐式(implicit)
由于篇幅问题,本章只讨论:
- 怎样使用密码来授权
- 使用JWT(JSON Web Token)来将信息编码在token中
- 怎样使应用更安全
如果想了解OAuth2的更多细节,推荐阅读:Justin Richer和Antonio Sanso的书:*OAuth2 in Action (2017)*。
7.2 一步一步来:使用Spring和OAuth2保护一个端点
最简单的方式:使用密码验证。需要做的有:
- 建立一个基于Spring Cloud的OAuth2认证服务
- 注册一个伪UI应用程序(作为一个已授权的应用程序),可以对用户身份进行验证和授权
- 使用OAuth2密码授权来保护EagleEye服务。不需要写UI,而是用Postman模拟用户登录,并使用OAuth2服务来验证身份
- 保护licensing和organization服务,使仅认证用户能够访问
7.2.1 建立EagleEye OAuth2验证服务
像其他部分一样,认证服务也是作为一个Spring Boot服务来运行的,需要首先添加需要的Maven依赖,然后为其设置一个启动类。需要的依赖有:
- spring-cloud-security
- spring-security-oauth2
认证服务启动类:
1 |
|
@EnableAuthorizationServer启动认证服务器;
添加路由:/user(实际上是/auth/user,/auth在认证服务的配置文件application.yml中声明contextPath)
被保护的服务将调用此端点,来验证token并检索来调用此服务的用户所拥有的角色及权限。
7.2.2 将客户端注册到OAuth2服务
将在OAuth2Config.java中把需要注册的客户端注册上去:
1 |
|
OAuth2的配置类继承了AuthorizationServerConfigurer(AuthorizationServerConfigurerAdapter也继承自AuthorizationServerConfigurer),后者是Spring Security的一个核心类。提供了一些验证key和授权的方法。需要重写两个方法:
- configure()方法,定义注册到认证服务上的客户端,入参为ClientDetailsServiceConfigurer类型。
- ada
我们再深入看一下第一个configure()方法。
ClientDetailsServiceConfigurer类支持两种不同的存储应用信息的方式:内存中和JDBC数据库中。本例使用*clients.inMemory()*方式。
*withClient()和secret()*方法提供了注册认证服务的应用名和密码,密码在服务调用认证服务时获取访问token时用。
authorizedGrantTypes()方法传入了一个逗号分隔的授予权限类型,本例中支持密码和客户端证书**授权。
scopes()方法定义调用认证服务的应用的类型。比如,Thoughtmechanix服务提供同一个应用的两个版本:一个web端,一个移动端。这些应用有相同的客户端名字和秘钥。当这个app向OAuth2申请key的时候,需要确定 是在哪个scope,确定了scope,才能给予适当的权限。需要注意的是,scope的定义与权限的定义不冲突,且优先级较高**,即,无论一个用户有什么权限,它还要有适当的scopes才能够对某个资源有访问权限。这种限制数据访问的实践(practice)在处理敏感用户信息时极为常见(如(病人)健康记录、税务信息)。
现在已经注册了一个应用,EagleEye。既然使用密码方式来验证,接下来要对用户设置对应的账户和密码。
7.2.3 配置EagleEye用户
已经设置好了应用级别的key和secret,可以为用户设置其单独的credentials和roles了。Spring存储/检索用户信息(用户的证书和角色)的地方有三种:内存、支持JDBC的关系型数据库、LDAP服务器。
LDAP服务器是什么?可以参考这个。
本例中,使用内存方式存储用户角色。定义两个用户账号:john.carnell、william.woodward;john.carnell拥有USER权限,william.woodward拥有ADMIN权限。
对每个用户的证书和角色的授予在WebSecurityConfigurer.java中实现:
1 |
|
定义的两个bean:authenticationManagerBean()、userDetailsServiceBean分别用来对用户进行验证和返回用户信息。